대학원 컴파일러 수업에서 ML을 이용하여 unroll and jam을 판별하는 모델을 학습을 하는 term project를 진행하였다.
unroll and jam pass는 이름에서 알 수 있듯이 loop 최적화에 관련된 pass로 unroll 과 jam을 수행하여 innermost loop body의 병렬성을 증가시켜서 제한된 resource의 utilization을 증가시키는 최적화이다.
내 기억이 맞다면 O2 이상의 최적화 부터 적용되는데 opt의 debug를 통하여 볼때 생각보다 잘? 사용이 안된다.
LLVM code를 보면 대부분 loop unroll과 loop fusion pass를 재활용하며 검사 정도만 하는데 이 때문에 da,lcssa,loop simplify가 조건을 만족하여도 unroll and jam pass가 동작되지 않는 경우가 많다.
대학원 컴파일러 수업에서 ML을 이용하여 unroll and jam을 판별하는 모델을 학습을 하는 term project를 진행하였다.
unroll and jam pass는 이름에서 알 수 있듯이 loop 최적화에 관련된 pass로 unroll 과 jam을 수행하여 innermost loop body의 병렬성을 증가시켜서 제한된 resource의 utilization을 증가시키는 최적화이다.
내 기억이 맞다면 O2 이상의 최적화 부터 적용되는데 opt의 debug를 통하여 볼때 생각보다 잘? 사용이 안된다.
LLVM code를 보면 대부분 loop unroll과 loop fusion pass를 재활용하며 검사 정도만 하는데 이 때문에 da,lcssa,loop simplify가 조건을 만족하여도 unroll and jam pass가 동작되지 않는 경우가 많다.
그래서 많은 시행착오를 끝에 알아낸것이 다음과 같은 최적화를 추가하면 수행이 된것이다.
아래는 행렬 연산의 예시이며 loop unroll and jam 이 수행되어야한다.
#define N 256
#define size 1024
int A[size][size];
int B[size][size];
int C[size][size];
void matmul() {
int i,j,k;
for (i=0; i < N; i++)
for (j=0; j < N; j++)
for (k=0; k < N; k++)
C[i][j] += A[k][i] * B[j][k];
}
clang -Xclang -disable-O0-optnone -emit-llvm matmul.c -S
opt -stats -debug -loop-unroll-and-jam -allow-unroll-and-jam -unroll-and-jam-count=2 matmul.ll
위처럼 해도 최적화가 수행안되는데 이걸로 삽질을 많이했다.
아래 pass를 추가하면 unroll and jam이 수행된다.
-mem2reg -simplifycfg -loop-rotate -instcombine
그리고 이걸하면서 cfg를 확인할 일이 있어 다음옵션을 유용하게 이용하였다.
opt -view-cfg matmul.ll 을 하면 다음과 같은 cfg가 나오며 xdot을 설치해야 볼수있다.(우분투에서는 sudo apt-get install xdot로 설치가능하다)
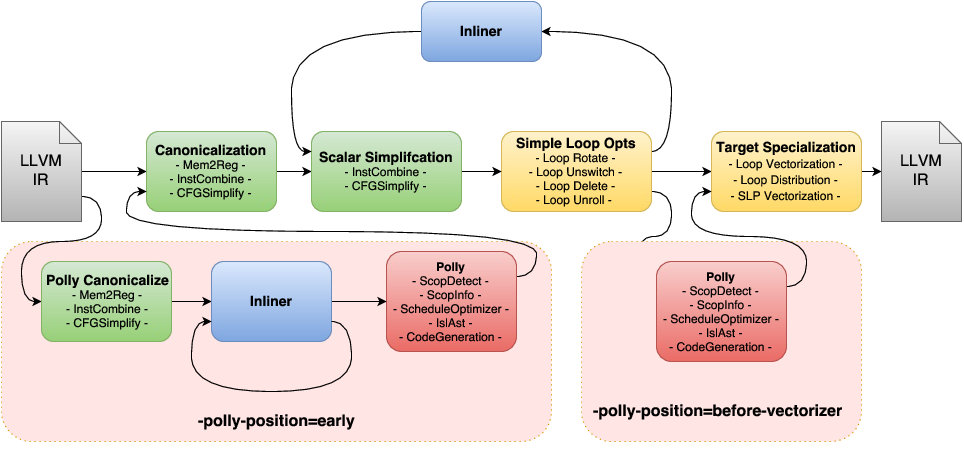
프로젝트의 결론 중 하나가 loop-unroll and jam은 결국 아래 다이어 그램에서 표기된 target independent 한 simple loop opt의 하나이므로 이것 하나의 수행 여부를 판별하는 것이 전체적인 최적화 pass의 성능 여부에 생각보다 큰 영향을 미치지 못한다는 것이다.(유감..)
아마 NAS에서 연구되는 방법을 사용하여 phase ordering 조금 더 섬세하게 하면 성능향상이 있을 것 으로 예상이 된다.