제목
NeuroVectorizer: End-to-End Vectorization with Deep Reinforcement Learning
저자
Ameer Haj-Ali, Nesreen K. Ahmed, Ted Willke, Sophia Shao, Krste Asanovic, Ion Stoica
Motivation
Compilers are designed today to use fixed-cost models that are based on heuristics to make vectorization decisions on loops. However, these models are unable to capture the data dependency, the computation graph, or the organization of instructions The vectorization is critical to enhancing the performance of compute-intensive workloads in modern computers.
Contribution
A comprehensive data set of more than 10,000 synthetic loop examples. An end-to-end deep reinforcement learning (RL) based auto loop-vectorization method
개인적인 느낌
search space가 너무 작아서 솔찍하게 의미가 있는지 의문.. /
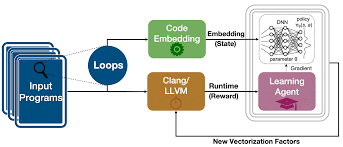
The Proposed Framework Architecture
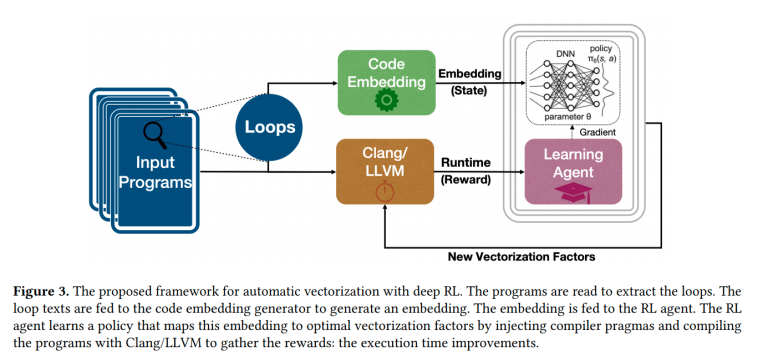
Code Embedding
- Code2vec(Embedding Network) represents a code snippet as a single fixed-length code vector, which can be used to predict the semantic properties of the snippet.
- This vector captures many characteristics of the code, such as semantic similarities, combinations, and analogies
 A code snippet and its predicted labels as computed by code2vec
reference
A code snippet and its predicted labels as computed by code2vec
reference
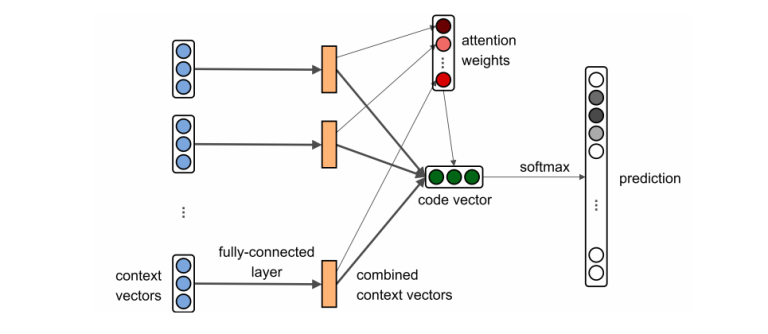 The architecture of our path-attention network. A full-connected layer learns to combine embeddings of
each path-contexts with itself; attention weights are learned using the combined context vectors, and used to
compute a code vector. The code vector is used to predicts the label.
reference
The architecture of our path-attention network. A full-connected layer learns to combine embeddings of
each path-contexts with itself; attention weights are learned using the combined context vectors, and used to
compute a code vector. The code vector is used to predicts the label.
reference
Automatic Vectorization Example

The RL Environment Definition
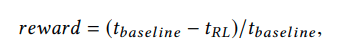 where baseline is the execution time when compiled with the currently implemented baseline cost model in LLVM and RL is the execution time when compiled with the injected pragmas by the RL agent
where baseline is the execution time when compiled with the currently implemented baseline cost model in LLVM and RL is the execution time when compiled with the injected pragmas by the RL agent
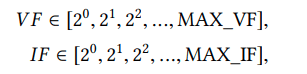 where MAX_VF and MAX_IF are respectively the maximum
VF and IF supported by the underlying architecture
where MAX_VF and MAX_IF are respectively the maximum
VF and IF supported by the underlying architecture
Dataset Description
 To speed up the training, and make it more efficient,
we built a dataset that includes loops only. We built generators that generate more than 10,000 synthetic loop examples automatically from the LLVM vectorization test-suite.
To speed up the training, and make it more efficient,
we built a dataset that includes loops only. We built generators that generate more than 10,000 synthetic loop examples automatically from the LLVM vectorization test-suite.
Handling Long Compilation Time
- During training, some of the programs took a long time to compile, mainly when the agent was trying to vectorize more than plausible
- giving a penalty reward of −9 (equivalent to assuming it takes ten times the execution time of the baseline) so that the agent will learn not to overestimate the vectorization and avoid it
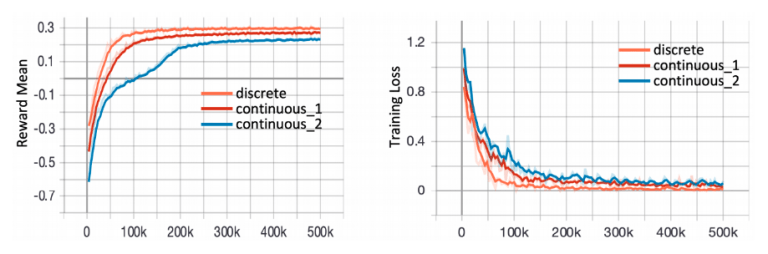
Results:Reward mean and training loss for different action space definitions
Results:The performance of the proposed vectorizer
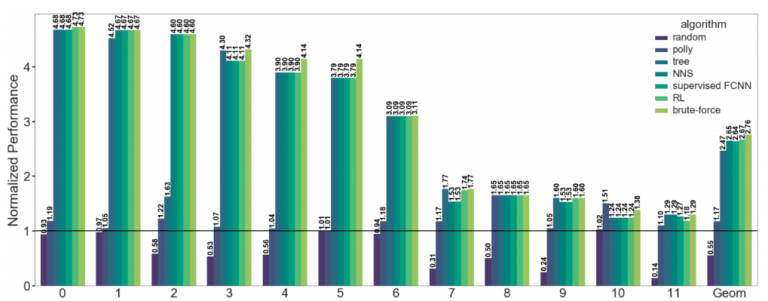 The performance is normalized to the baseline(VF = 4, IF =
2)
The performance is normalized to the baseline(VF = 4, IF =
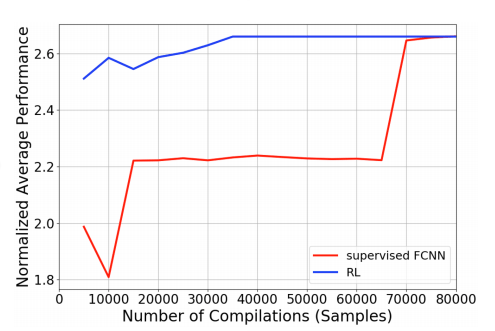
2)Results:Normalized average performance of supervised FCNN and deep RL
Results:The performance of the proposed vectorizer on
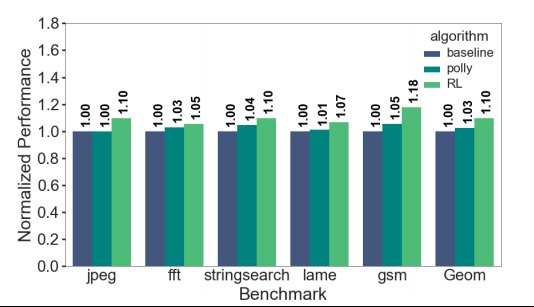 Mibench compared to Polly and the baseline cost model
Mibench compared to Polly and the baseline cost model
The performance is normalized to the baeline(VF = 4, IF = 2)
references
https://arxiv.org/abs/1909.13639