제목
DARTS: DIFFERENTIABLE ARCHITECTURE SEARCH
저자
Hanxiao Liu,Karen Simonyan,Yiming Yang
Motivation
기존 NAS가 상당수의 시간 혹은 cost가 필요(2000 GPU days of reinforcement learning, 3150 GPU days of evolution)이러한 원인 중 하나가 discrete domain, which leads to a large number of architecture evaluations required 때문이라고 분석. 물론 이전에도 filter size와 같은 것들을 연속적으로 학습 했으나 해당 논문은 블록, 그래프 토플로지 까지 학습하는 것을 목표로 함
Contribution
- 기존의 discrete and non-differentiable search space에서 RL혹은 GA를 이용하던 NAS를 아키텍쳐의 표현을 bilevel optimization을 사용하여 gradient descent로 학습 하게 함.
- extensive experiments on image classification and language modeling (좋은 결과)
- 기존 방법에 비하여 학습 시간을 줄임
- CNN,RNN에서 transferable 함을 보임
CONTINUOUS RELAXATION AND OPTIMIZATION
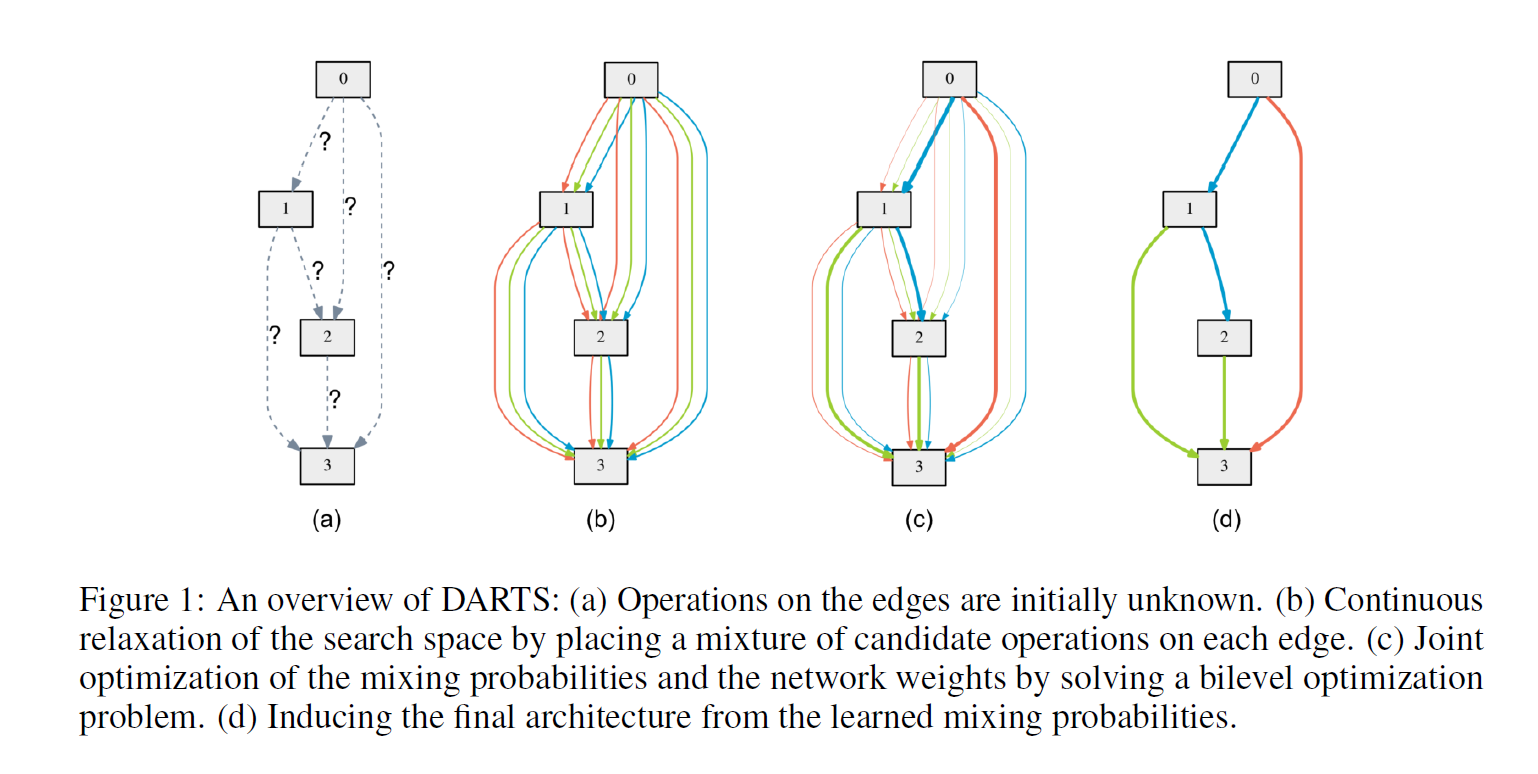
위 그림과 아래 수식을 통해서 어떠한 방식을 통하여 연속적으로 연산을 정의 하는지 알 수 있다. node$i$,$j$연산의 종류를 선택하는 방법은 아래 식처럼 $\alpha$의 softmax를 이용하는 것이고 이는 위 그림을 통하여 직관적으로 알 수 있다.
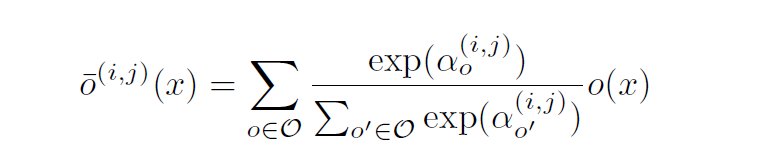
building block을 위에서 정의 했으니 weight를 학습하며 final architecture를 정해야 한다.
이는 아래와 같이 bilevel optimization을 사용한다.
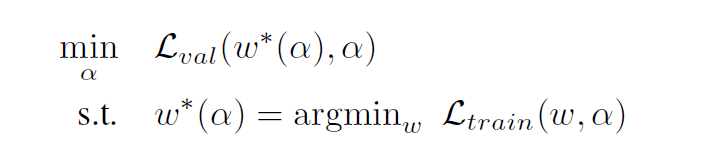

APPROXIMATE ARCHITECTURE GRADIENT
개인적으로는 design choice로 보이며 관련 후속논문이 있기때문에 크게 중요한 내용은 아닌것 같다. 위 bilevel optimization form을 보면 MAML의 수식이 떠오른다. 이 논문에서도. First-order Approximation을 포함하여 연산량 감소를 위하여 수식을 변형 하였다.(trade-off가 있기 때문에 상황에 맞춰야)
DERIVING DISCRETE ARCHITECTURES
discrete architecture를 만들기 위해서 top-k strongest operations만 선택 (zero는 예외)
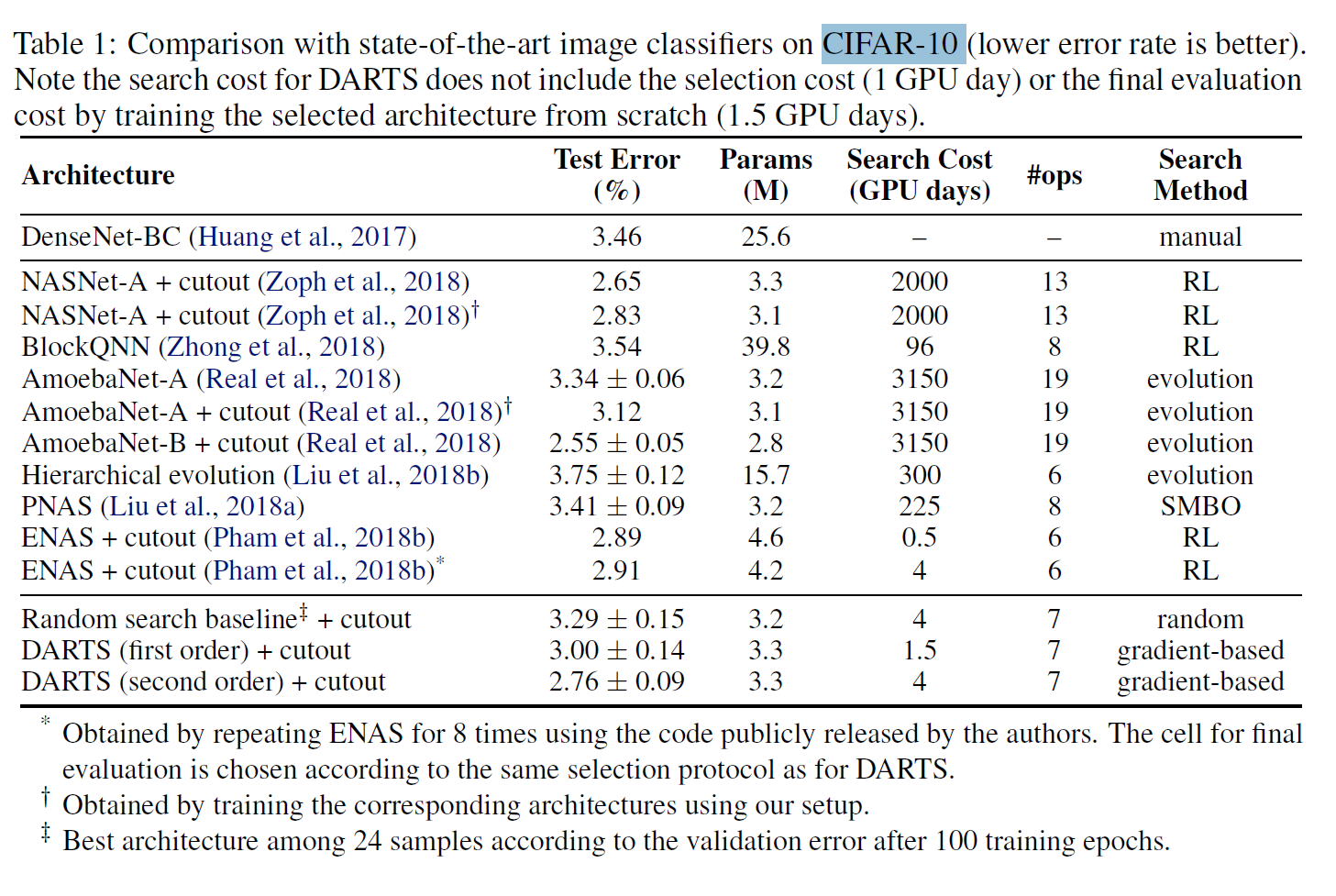
Results
NASNET-A(2000 GPU days),AmoebaNet-A(3150 GPU days) ENAS (0.5 GPU day)에 비하여 동일 파라라미터를 맞췄을때 상당하게 시간 측면에서 효율적인 결과를 보여줌
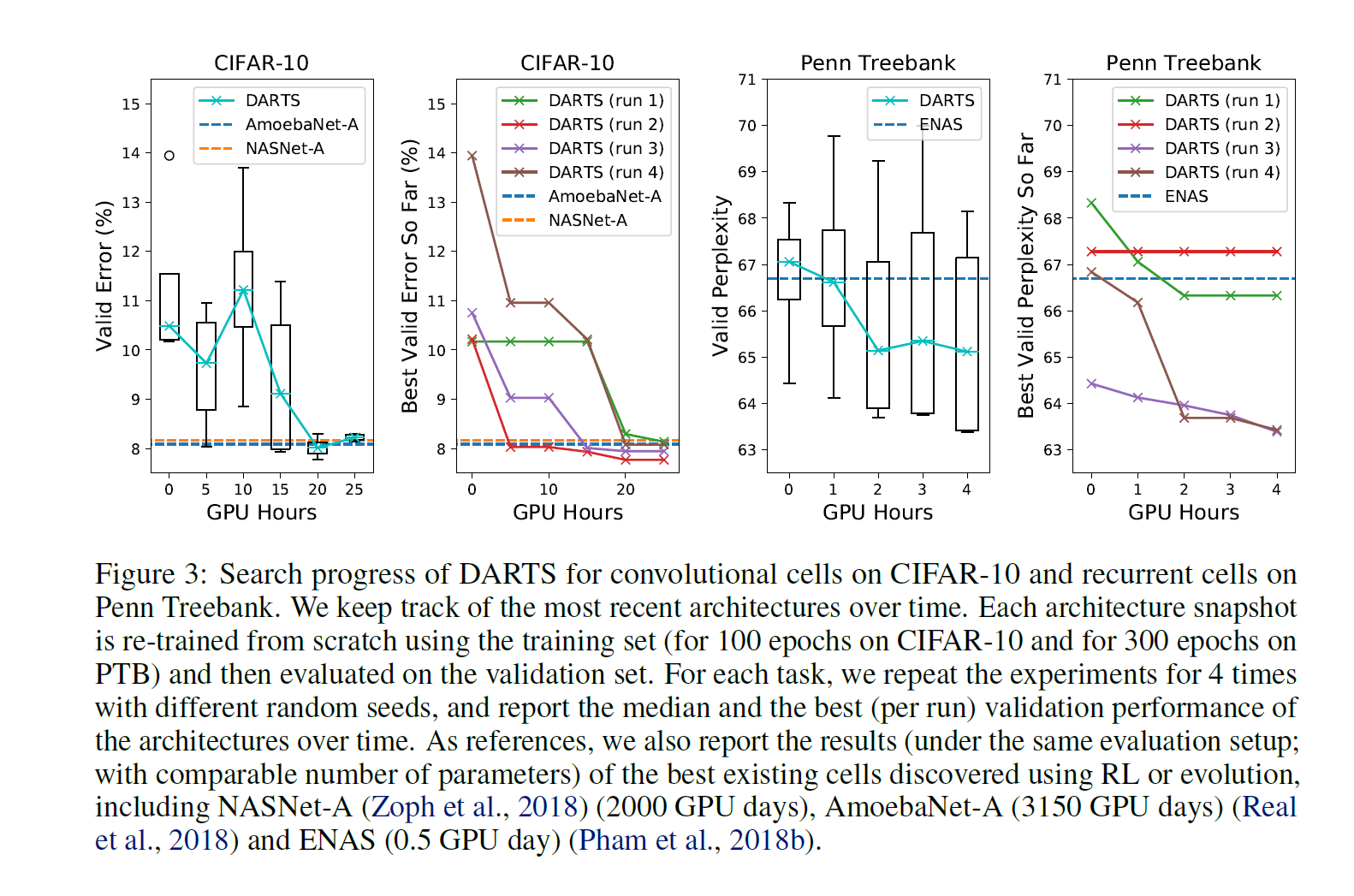
cifar10
PTB
ImageNet in the mobile setting